Explaining Load Balancers
How Real Systems Distribute Traffic at Scale
Sia was a CSE student. One day she built an AR/VR based gaming project. Unexpectedly it blew up overnight. There were too many users and her netlify free suscription servers could not handle the load. To solve the problem she rented some servers. However users were still furious over the slow speed, she found that some servers were working more than others. Sia was burning her money on servers but nothing seemed to work. That’s when ChatGPT advised her to use load balancers.
Learn about load balancing now so your fate is not the same as Sia.
What happened when their was no system to distribute incoming requests to the multiple servers ?
Some servers were overused, leading to failures while others were still available. Poor utilisation of expensive servers.
The website could not meet the demands of it’s users - Latency spikes
Users whoose requests were going to the overloaded servers could not play the game. The servers became the single point of failure.
What happens when you really want to visit a site but it keeps slowing down ? You hit refresh and retry consistently. That only adds up to the problem. It even has a name “Thundering Herd Problem”. Imagine a herd of bulls (user requests) thundering towards you(server). Ofcourse you (and your server) get trampled. The spike in traffic from the retry’s is worse than the orignal load.
What happened when Sia introduced load balancing ?
Since no single machine was overloaded while others remained idle, the capacity was used optimally. Latency stopped spiking because the high pressure was spread evenly across. Some advantages of load balancers :
Better resource utilization
Lower latency
Controlled degradation in case of extreme loads
Horizontal scalability
*For better understanding ensure that you understand the following terms. A quick description for these is provided in the glossary at the end of article
DNS Servers,
L4 and L7 of TCP/IP
Request Flow
Stateful/Stateless servers
Failure Modes
—How do load balancers work ?
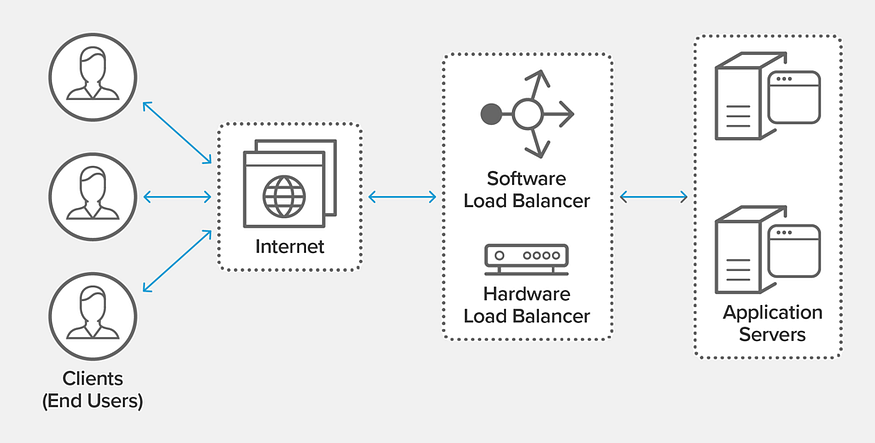
When you type into a library’s search bar for a book here’s what happens:
your request is sent to an IP which is returned by the DNS (usually the load balancer’s ) → load balancer recieves the connection → using it’s routing model and algorithm, it selects a backend from the set of healthy servers → forwards(or terminates) request to the server → server processes and returns response → loadbalancer relays it back to client
This is the general request path; the next sections explain how the load balancer manages connections and chooses a server.
In real systems load balancing usually happens at two levels. An outer layer for quick and basic distribution based on network information like IP addressand port number. And a deeper layer for intelligent routing based on content such as URL, HTTP header, cookies.
The two layers are : L4[Transport Layer] and L7[Application Layer]

At L4 the balancer forwards the packets and tracks it’s connections using the 5-tuple : [src IP, destination IP, src port, destination port, protocol]. It cannot inspect application level data, but this makes it fast and efficient for high volume traffic.
At L7 it understands the protocol. It can terminate TCP/TLS, inspect URLs, headers, cookies, and route accordingly. This makes it powerful and flexible but also more expensive in terms of latency and compute.
This distinction determines what algorithms are possible, what metadata can be used and how much latency you pay.
Health checks are automated probes used to monitor the status of backend servers. Load balancers periodically send these probes(e.g. HTTP requests or TCP pings) to each server. If a server fails the health check, the balancer temporarily removes it from the pool of servers that can recieve requests. When the server passes subsequent health checks it’s added back into rotation. This ensures that traffic is only sent to healthy servers, preventing failures from affecting users.
How load balancers decide where to forward requests ?
There are multiple algorithms which decide how a load balancer distributes requests to their pool of servers.
Static
Round Robin
Sticky Round Robin
Weighted RR
General Hashing
Dynamic
Least Connections
Least Time
Consistent Hashing
Static algorithms work without taking into account the servers real time conditions and performance metrics. These algorithms have the common advantage of being simple to implement and usefull in stateless applications, and also have the same disadvantage of lower preciscion and adaptivity.
Round Robin
Working : Sends first request to server 1 → next to 2nd →...→nth request to nth server → n+1th to 1st server and so on.
Advantage : Simple to implement and easy to understand
Disadvantage : Can overload servers if request or server capacities are not uniform. Some requests consume more CPU, memory, or I/O than others. RR uniformly distributes non-uniform requests. Similarly server capacities may also differ thus a comparitively slower server can become a bottleneck in RR.

Sticky Round Robin
Working: Extension of RR. Sends requests from same user to same server, trying to improve performance by keeping related data randomized.
Disadvantage: Flawed assumption as request from same user don’t guarantee similiar requests so it can(and will especially in stateless apps) create uneven load across servers
Advantage: Used in legacy stateful applications where session affinity improves performance, but often avoided in modern stateless architecture.

Weighted Round Robin
Working : It assigns priorty to servers by setting their weights. Server with higher weight recieve proportionally higher requests.
Advantage : Solves the problem of non uniform server capacities.
Disadvantage: The weights are manually configured, hence not adaptible to real life changes

General Hashing
Working: A hash function maps incoming requests to the servers using a key such as the client’s IP, user ID, requested URL, etc. Requests with the same key are consistently routed to the same server.
Advantage: Deterministic routing ensures that requests for the same key usually hit the same server, which can improve cache locality and session affinity
Disadvantage: Effectiveness depends on the hash function. If not optimal it can lead to uneven load distribution
The Churn Problem : When a server leaves or joins the pool, the hash function remaps almost all the keys to the new servers. This can break active sessions, overload some servers, and invalidate cached data.

Dynamic Algorithms factor in real time metrics such as the number of connections, latency and response time
Least Connections
Working: It tracks the number of ongoing connections on each backend server and sends each request to the server with least number of active connections or open requests
Advantage : Requestes are routed to servers with most remaining capacity.
Disadvantage : The algorithm assumes equal server capacity. For non-heterogenous servers this algorithm can lead to overloading while other servers are available

Least Time
Working : The load balancer estimates the expected total response time for each server, combining the current queue length (or active connections) and the average service time per request. It forwards the incoming request to the server with the lowest estimated completion time.
Advantage: More intelligent than simple Round Robin or Least Connections. It accounts for both server load and request complexity, reducing the risk of overloading busy servers.
Disadvantage: Requires accurate monitoring of server load and request times. Misestimation can lead to suboptimal routing. More computationally expensive than simpler algorithms.
Consistent Hashing*
Working: Consistent Hashing is a distributed hashing scheme that assigns both servers and keys to positions on an abstract hash ring. Each request is routed to the first server clockwise from its hashed key. When a server is added or removed, only the keys that fall between the affected server and its neighbors are remapped.
Advantage: Minimizes disruption when the server pool changes. Only a small fraction of keys move, preserving cached data and active sessions. Scales well in large, dynamic environments. In general only K/N number of keys are remapped in such cases. (K : No. of Keys, N: No. of servers)
Disadvantage: Slightly more complex to implement than naive hashing. Load imbalance can occur if servers are not virtualized (i.e., mapped multiple times on the ring).
Solving the Churn Problem: Unlike naive hash-based routing, consistent hashing only remaps keys that are directly affected by a server joining or leaving. This ensures most keys continue hitting the same server, avoiding massive cache invalidation or session disruption.

When Things Go Wrong As They Sometimes Will…
Traffic is neither smooth nor predictable. Even perfect algorithms tumble when arrival rate exceeds service rate. At that point the system must choose how to fail. The major strategies for controlled failure are:
- Backpressure is a mechanism where a system explicitly signals upstream components to slow down instead of continuing to accept work it cannot handle. Before backpressure, the system keeps accepting requests and gradually degrades. During, pressure is pushed upstream and demand is throttled. After, healthy traffic is protected and the system remains recoverable instead of collapsing under queued work. This includes :
Stop accepting new connections
Return fast failures (503, 429)
Reduce per-client concurrency
Failing fast protects healthy traffic and keeps the system recoverable.
Load shedding is the deliberate act of dropping a portion of incoming requests once capacity is exceeded. It is a conscious trade-off: sacrificing some requests to preserve overall system health. Before shedding, latency grows and resources saturate. During, excess traffic is rejected quickly and predictably. After, the system continues serving the majority of users reliably. Losing 5% of requests cleanly is far preferable to letting 100% fail through timeouts.
Timeouts define an upper bound on how long a system will wait for a response at each hop. Without timeouts, slow or stuck requests accumulate, consume resources, and block progress.
Cascading failure is when large parts of the system go down together. Backpressure, load shedding, and timeouts exist primarily to break this chain early and keep failures isolated rather than systemic.
Balancing the Load Balancers
In real-world, high-traffic systems there is rarely a single load balancer. Instead, multiple load balancers are deployed in tiers to handle scale and failure. When a user makes a request, DNS (or a global traffic manager) returns the IP address of one of several available load balancers. This layer effectively balances traffic across load balancers, providing redundancy and geographic or capacity-based routing. Once the request reaches a specific load balancer, it applies its configured logic: L4 or L7 routing, health checks, and algorithms to distribute the request to a healthy backend server.
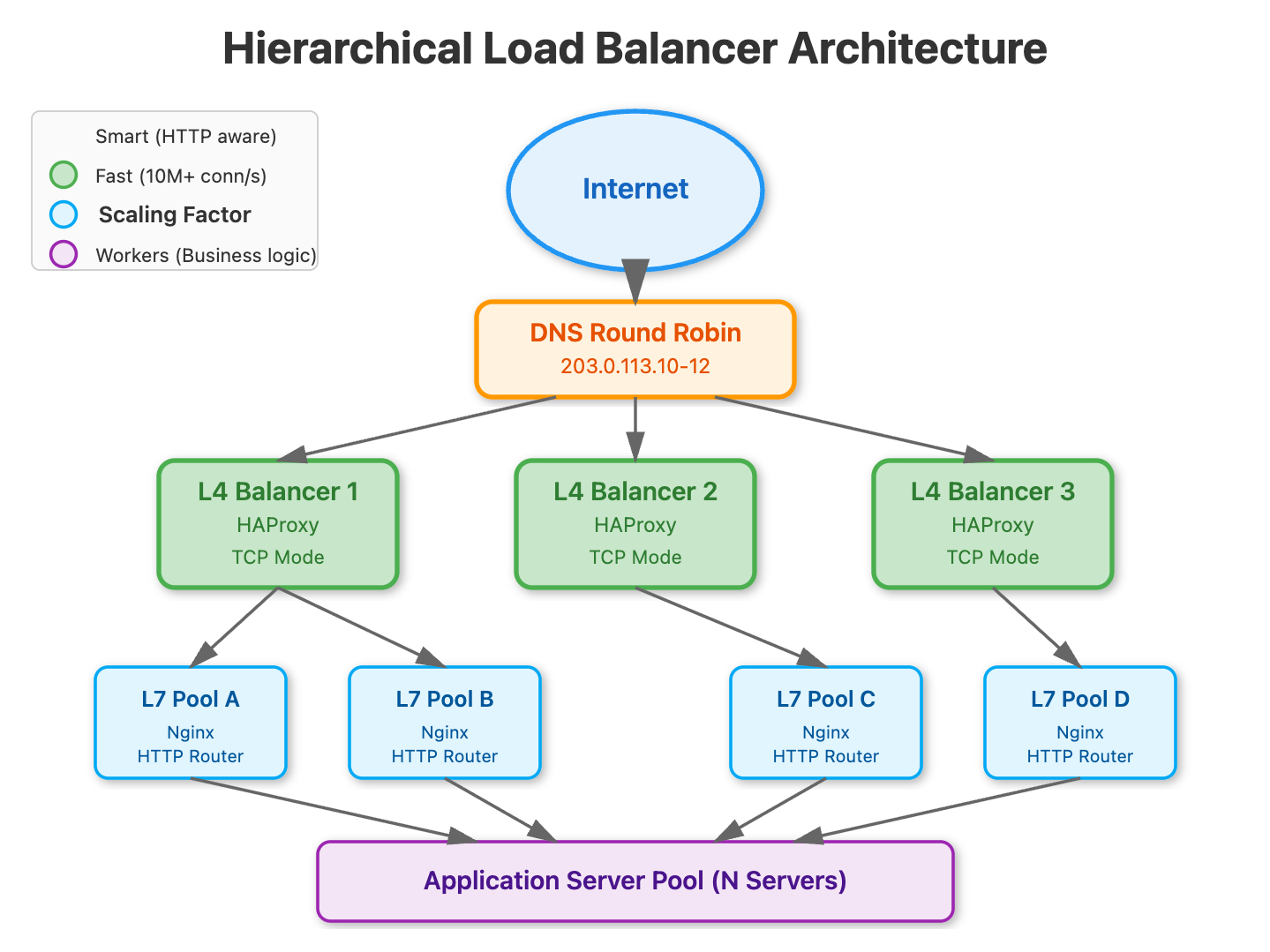
DNS sits at the top of Load Balancers and uses coarse-grained techniques, not real-time load balancing.The simplest is DNS Round Robin, where different IPs are rotated per query, but it reacts slowly due to caching (TTL).More advanced setups use GeoDNS to return region-closest IPs or Anycast to route users to the nearest data center at the network level.Some providers add health-aware DNS (GSLB), but even then DNS decisions are slow and best used only for entry-point distribution, not fine control.
This hierarchical setup avoids a single point of failure, allows the system to scale horizontally, and ensures traffic can continue flowing even if individual load balancers go down.
Glossary
DNS Servers : DNS (Domain Name System) servers translate human-readable domain names into IP addresses. They act as the first routing decision in most distributed systems, deciding which entry point a client will hit. DNS operates at a coarse level: it does not see application load or per-request latency. Because of caching and TTLs, DNS responses are slow to change, which makes DNS suitable for global traffic steering (regions, availability zones, failover) but unsuitable for fine-grained load balancing.
L4 and L7 of TCP/IP : Layer 4 (Transport Layer) load balancing operates on network metadata such as source IP, destination IP, ports, and protocol. It forwards packets without understanding application data, making it fast, scalable, and low-latency.
Layer 7 (Application Layer) load balancing understands the application protocol (HTTP, HTTPS, gRPC). It can inspect URLs, headers, cookies, and terminate TLS, enabling intelligent routing and advanced policies. This power comes at the cost of higher latency, more compute usage, and increased operational complexity.Request Flow : A typical request flow begins with DNS resolving a domain to a load balancer’s IP. The client establishes a connection with the load balancer, which selects a backend server from the healthy pool using a routing algorithm. Depending on the layer, the load balancer either forwards the connection (L4) or terminates and re-initiates it (L7). The backend processes the request and sends the response back through the load balancer to the client.
State/Stateless servers : Stateless servers do not store client-specific session data between requests. Any request can be handled by any server, making scaling and failure recovery simple and reliable.
Stateful servers maintain session data locally, tying users to specific servers. This can improve performance in some cases but complicates load balancing, scaling, and failover, often requiring sticky sessions or external state stores.Failure Modes : Failure modes describe how components behave when things go wrong. Common failures include server crashes, slow responses, partial network outages, and cascading failures due to overload. Load balancers mitigate failures through health checks, timeouts, retries, and circuit breaking.
Image sources
Algorithm 1-5 : https://www.youtube.com/watch?v=dBmxNsS3BGE
Hierarchial Load Balancing Architecture: https://systemdr.substack.com/p/scaling-the-load-balancer-layer-from
